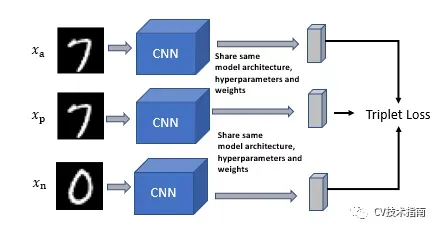
Siamese Network
- Siamese 网络采用两个不同的输入,通过两个具有相同架构、参数和权重的相似子网络。
- 这两个子网互为镜像,就像连体双胞胎一样。 因此,对任何子网架构、参数或权重的任何更改也适用于其他子网。
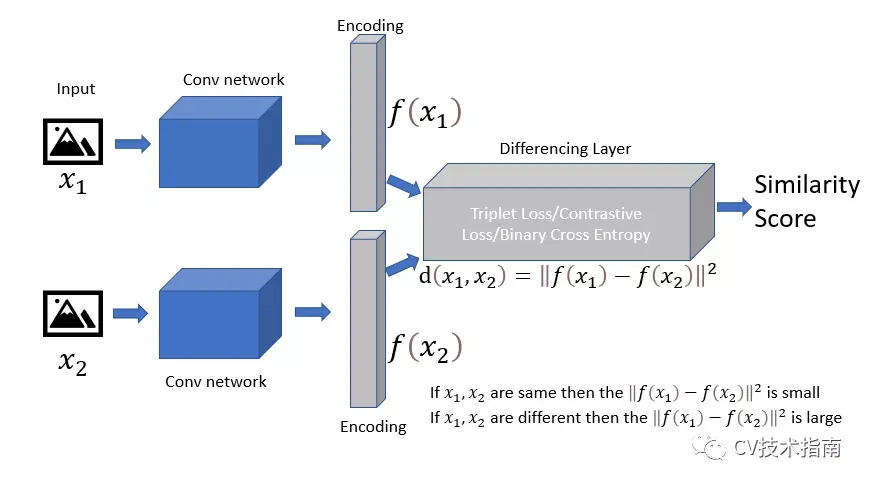
- 两个子网络输出一个编码来计算两个输入之间的差异。
- Siamese 网络的目标是使用相似度分数对两个输入是相同还是不同进行分类。可以使用二元交叉熵、对比函数或三元组损失来计算相似度分数,这些都是用于一般距离度量学习方法的技术。
- Siamese 网络是一种one-shot分类器,它使用判别特征从未知分布中概括不熟悉的类别
train
- 加载包含不同类的数据集
- 创建正负数据对。 当两个输入相同时为正数据对,当两个输入不同时为负数据对。
- 构建卷积神经网络,它使用全连接层输出特征编码。我们将通过姊妹 CNN传递两个输入。姐妹 CNN 应该具有相同的架构、超参数和权重。
- 构建差分层以计算两个姐妹 CNN 网络编码输出之间的欧几里得距离。
- 最后一层是具有单个节点的全连接层,使用 sigmoid 激活函数输出相似度分数。
- 使用二元交叉熵作为损失函数。
eval
- 向训练模型发送两个输入以输出相似度分数。
- 由于最后一层使用 sigmoid 激活函数,它输出一个范围在 0 到 1 之间的值。接近 1 的相似度得分意味着两个输入是相似的。接近 0 的相似度得分意味着两个输入不相似。一个好的经验法则是使用 0.5 的相似性截止阈值。
应用
- 签名验证
- 面部识别
- 比较指纹
- 根据临床分级评估疾病严重程度
- 工作资料的文本相似度以恢复匹配
- 用于配对相似问题的文本相似度
优缺点
- Siamese 网络是一种one-shot分类模型,只需一个训练样本即可进行预测。
- 对类别不平衡更鲁棒,因为它需要很少的信息。 它可以用于某些类的样本很少的数据集。
- Siamese 网络的one-shot学习特性不依赖于特定领域的知识,而是利用了深度学习技术。
- 仅输出相似性分数而不输出概率。互斥事件的概率总和为 1。而距离不限于小于或等于 1。
loss
在 Triplet loss 中,anchor和正样本编码之间的距离被最小化,而anchor和负样本编码之间的距离被最大化。